As a regression problem to spatially separated bounding boxes and
associated class probabilities
A single neural network predicts bounding boxes and class probabilities directly from
full images in one evaluation
more localization errors but is less likely to predict
false positives on background
The YOLO Detection System
resizes the input image to 448 × 448
runs a single convolutional network on the image
thresholds the resulting detections bythe model’s confidence
The Model
Procedure
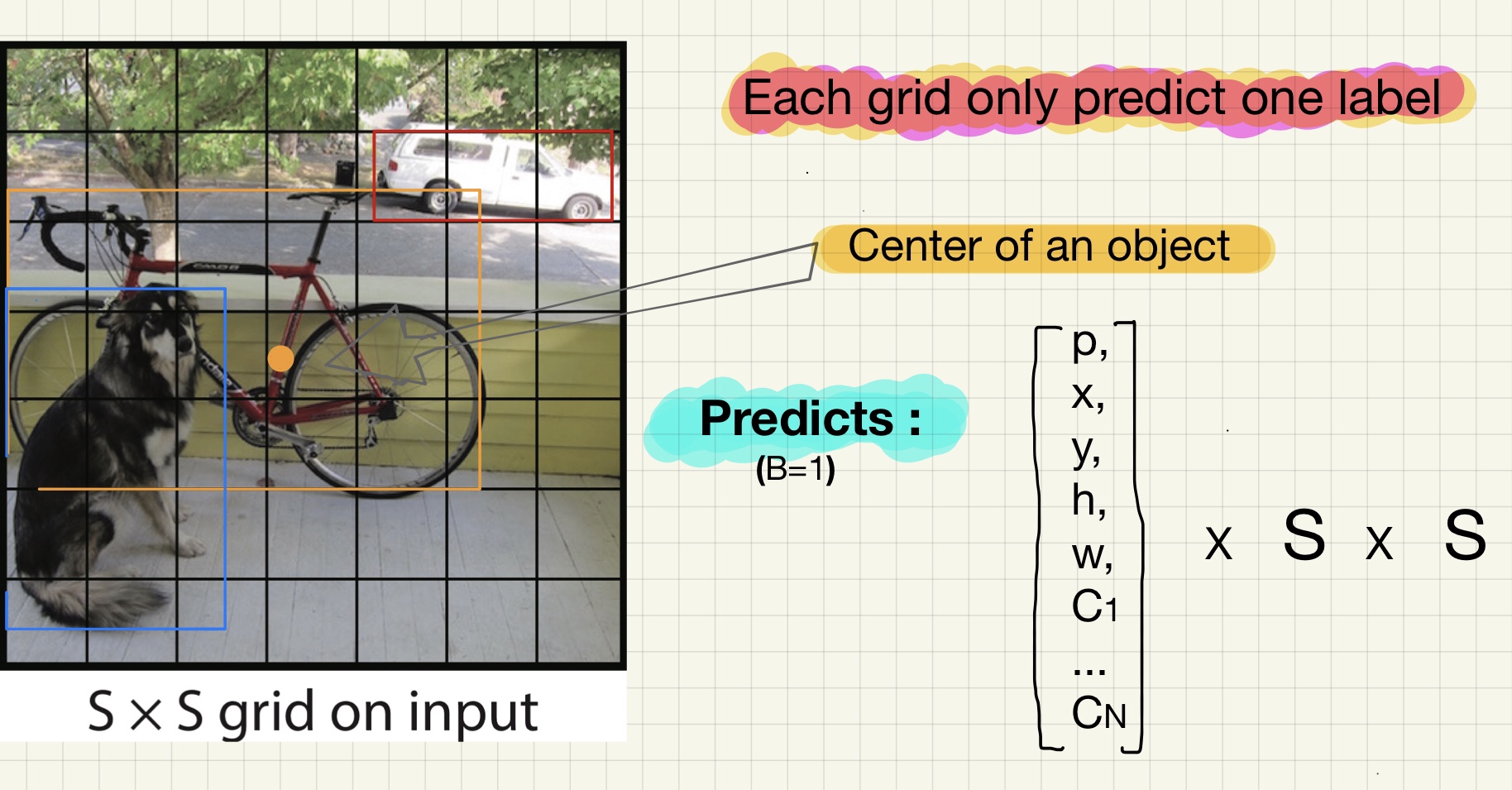
It divides the image into an S × S grid [448 × 448 -> 7 x 7] If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
Each grid cell predicts B bounding boxes, confidence for those boxes, and C class probabilities. Bounding Box: x, y, w, h(center) Confidence: Pr(object)⋅IoUpredtruth